|
据Science 报道,Scientific Reports 副主编Matt Spick发现大量利用美国国家健康与营养调查(NHANES)数据的公式化论文大量涌入Scientific Reports、PLOS Biology等期刊中。这些低质论文的激增,可能是由“论文工厂”主导,并通过AI生成文本提供便利。
Nature 也在近期的报道中指出,除了NHANES,其他生物医学数据库(UK Biobank、FAERS、GBD和FinnGen)也频繁被这些低质论文利用。  
面对这一问题,Journal of Global Health 已经率先采取行动,收紧了对基于这些数据库的论文的审核标准。现在,使用开放数据集投稿的作者必须声明过去三年内使用类似数据集发表过多少篇论文,披露是否使用人工智能撰写手稿,并解释其如何排除结果中的假阳性。
为应对“滥用数据集”的趋势,其他期刊和出版商或将效仿Journal of Global Health,引入类似的严格审核机制。
1 绝大部分低质论文来自中国 FinnGen成重灾区
根据Matt Spick、Anthony Onoja等人的研究,2021年-2025年间,有六个数据集的论文数量远超预期增长,其中NHANES、UK Biobank、FAERS、GBD和FinnGen这五个数据源的“模板化”论文爆发式增长。
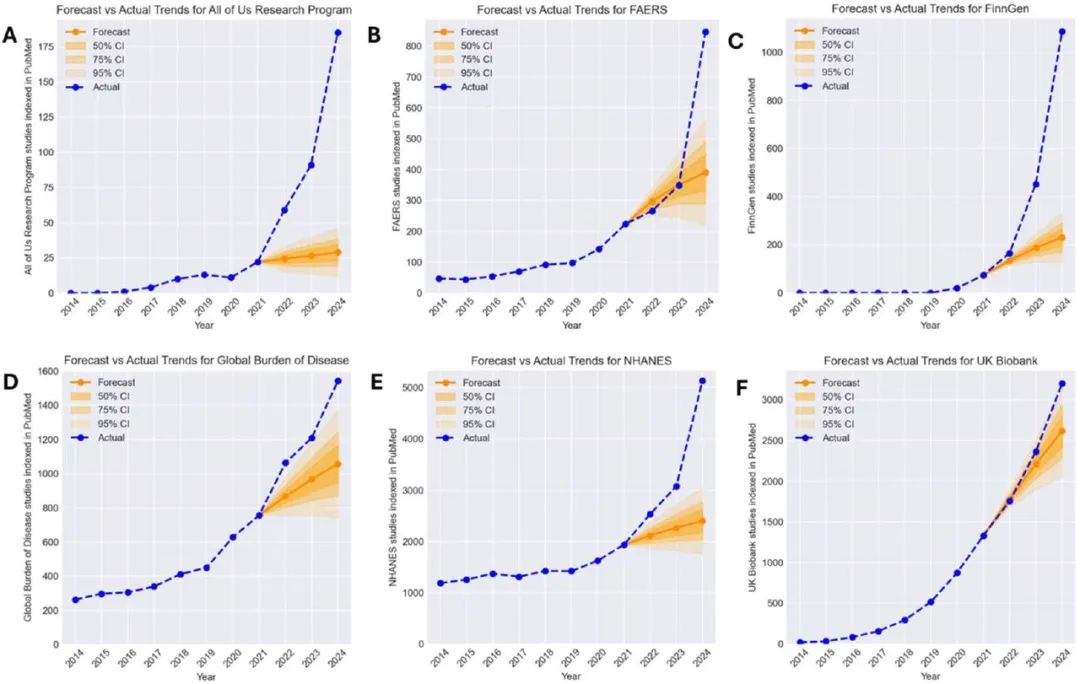 与ARIMA预测相比的六个数据源实际出版数量 这些低质论文往往选取某种健康问题、关联的环境或生理因素,以及特定人群的已公开数据,通过简单替换变量生成所谓的“新发现”,如饮用半脱脂牛奶与预防抑郁症(PMID 39703337)或受教育程度与术后腹疝(PMID 39616067)之间,以及许多其他缺乏生物学基础的假设。
在检查这六个数据源论文的地理来源变化时,研究发现来自中国的论文从2021年占PubMed数据库索引论文的19%猛增至2024年的65%,为所有国家/地区中增长最多的。在这六个数据集中,FinnGen数据源的中国论文增长最为显著,截至2024年,89%相关论文的主要作者来自中国。 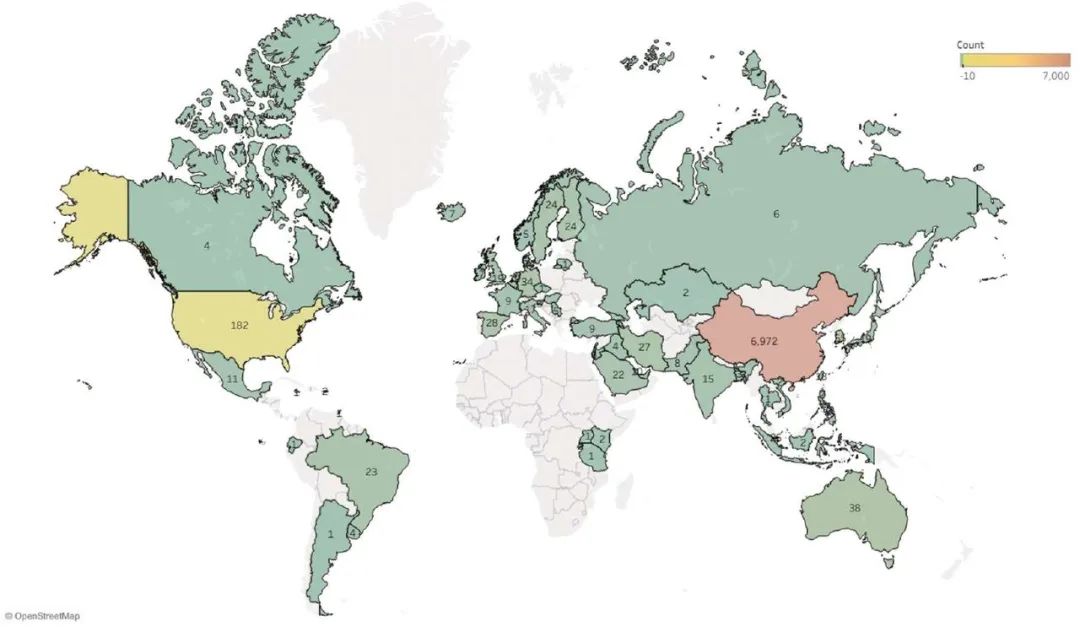 2021年至2024年PubMed中编入索引的论文增加的国家/地区 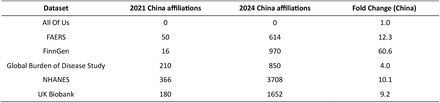 六个数据的中国论文增长情况
这种论文产出的不平衡分布表明,这种增长并非研究生产力的普遍提高,而是发展中国家的研究人员在“不发表就灭亡”的学术压力下,因缺乏科研支持而铤而走险,最终助长了”论文工厂“的发展。 2 五大生物医学数据库简介
NHANES(美国国家健康与营养检查调查)
基本介绍:由美国疾控中心(CDC)主导,始于1960年代,1999年起转为持续项目,每年调查约5,000名美国代表性人群。 数据内容: 特点: UK Biobank(英国生物样本库)

基本介绍:覆盖50万英国志愿者,历时15年收集基因组、生活方式及健康数据,2025年完成全球最大规模全身体成像项目(10万人)。 数据亮点: 突破性应用: 数据访问:研究者需申请,已支撑1,300+篇论文。
FAERS(FDA不良事件报告系统)

基本介绍:FDA用于监测上市后药品安全性的数据库,接收医疗专业人员/消费者的自愿报告。 数据结构: 局限性: 数据访问:官网免费开放(TXT格式),含7个表(DEMO/DRUG/REAC等)。
GBD(全球疾病负担研究) 
基本介绍:由华盛顿大学健康指标与评估研究所(IHME)主导,覆盖204个国家/地区、300+疾病、70+风险因素,数据追溯至1990年。 核心指标: 优势: 数据访问:官网免费开放,可通过GBD Compare勾选参数(疾病、地区、年份、指标如DALY/死亡率),直接下载CSV文件。
FinnGen(芬兰基因组计划) 
基本介绍:2017年启动的公私合作项目,整合50万芬兰人基因组与电子健康记录,利用芬兰人群遗传独特性(基因隔离)解析疾病机制。 数据进展: 独特价值: 数据访问:通过学术合作申请或等待1年保护期后公开(存于FinnGen Release Portal)。  本文内容来源于科研大匠,版权归原作者所有,如有侵权请联系删除,谢谢!
|  |Archiver|手机版|小黑屋|Octave中文网学术交流论坛
( 黑ICP备2024030411号-2 )
|Archiver|手机版|小黑屋|Octave中文网学术交流论坛
( 黑ICP备2024030411号-2 )
 发表于 2025-9-5 21:50:57
发表于 2025-9-5 21:50:57