刚刚,DeepSeek-R1登上了Nature封面! 作者排序按拼音首字母,DeepSeek 创始人兼 CEO 梁文峰为该论文的通讯作者。 今年1月,DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning论文发布,如今成功登上全球顶刊封面,用RL为大模型推理能力开辟了全新路径。  与今年1月发布的DeepSeek-R1的初版论文相比,本次论文披露了更多模型训练的细节,并正面回应了模型发布之初的蒸馏质疑。
在封面推荐中,Nature毫不吝啬地赞扬了DeepSeek-R1的成就:目前几乎所有主流的大模型都还没有经过独立同行评审,这一空白“终于被DeepSeek打破”。  值得一的是,补充材料首次公开了R1训练成本——294000美元,数字低到惊人。 即便是加上约600万美元的基础模型成本,也远低于OpenAI、谷歌训练AI的成本。  从一篇arXiv论文到Nature封面,DeepSeek团队再次用实力为AI推理的未来铺路。  文章一经上线,也引起了大家的广泛关注,更有网友笑评:这波属实是Nature高攀了。 文章一经上线,也引起了大家的广泛关注,更有网友笑评:这波属实是Nature高攀了。    揭秘DeepSeek-R1「炼丹炉」 揭秘DeepSeek-R1「炼丹炉」接下来,就让我们深入这个「炼丹炉」的内部,一探究竟。 GRPO算法 在AI训练的赛道上,强化学习算法PPO(近端策略优化)长期以来都是大语言模型训练的「标配赛车」。它虽然强大,但也以资源消耗巨大和实现复杂而著称。 DeepSeek团队选择了一条更聪明的路,他们采用了GRPO(组相对策略优化)算法作为核心驱动引擎。  PPO就像一位极其谨慎的教练,它在每次训练更新时,都会严格限制新策略与旧策略的偏离程度,以防模型「跑偏」导致训练崩溃。 这种谨慎是有代价的,它需要大量的计算来维持稳定。 而GRPO则像一位更高效、更相信「集体智慧」的教练。它的核心思想是: 在每次训练时,让模型针对同一个问题,生成一组(比如16个)不同的答案。然后,它不只是简单地奖励最好的那个,而是根据这一组答案的「相对好坏」,来整体优化模型。 具体来说,它会计算出每个答案相对于这一组答案平均水平的「优势」(Advantage),优势大的(即表现更好的)答案会得到更大的激励权重,而表现差的则会被抑制。 这种「组内竞争、择优而学」的机制,简化了PPO复杂的约束过程,不仅显著降低了资源消耗,还被证明在实践中同样稳定高效。 奖励设计 强化学习的本质,就是通过奖励(Reward)来塑造模型的行为。它决定了模型将朝着哪个方向进化。 为此,DeepSeek团队设计了一套双轨制的奖励系统。 1. 基于规则的奖励 对于推理任务(数学、编程、逻辑),团队采用了一套极其严格的基于规则的奖励系统。 准确率奖励:最终答案对不对?对于数学题,答案必须和标准答案完全一致;对于编程题,代码必须通过所有预设的测试用例。 格式奖励:思考过程是否符合规范?所有的思考过程都必须封装在<think>和</think>标签内。  这里,有一个关键的决定:在推理任务上,完全不使用基于神经网络的奖励模型。 因为团队发现,AI在长时间、大规模的强化学习中,会找到奖励模型本身的漏洞并加以利用,即所谓的「奖励投机(Reward Hacking)」。 2. 基于模型的奖励 然而,世界并非非黑即白。对于通用任务比如写作、对话,大多只有好坏之分。 于是,DeepSeek团队引入了基于模型的奖励,从而让模型更符合人类的偏好。 有用性奖励模型:专门负责评判模型的回答对用户是否有用、切题。它通过比较大量的「好答案」与「坏答案」对(由DeepSeek-V3生成并筛选)来学习人类的偏好。有趣的是,它只评估最终的摘要部分,而不去干涉底层的推理过程,给予模型在思考上的充分自由。  安全奖励模型:负责检查模型的全部输出,包括思考过程,以识别和惩罚任何潜在的有害、偏见或危险内容。  如此一来,模型在保持强大推理能力的同时,也学会了如何生成更有用、更安全、更符合人类习惯的内容。  训练细节
DeepSeek的训练并非一蹴而就,而是分为多个精心设计的阶段,每个阶段都有不同的侧重点和巧妙的参数调整。 最开始的训练完全聚焦于数学、编程等推理任务,仅使用基于规则的奖励。  一个有趣的现象发生在训练进行到第8,200步时:研究人员将模型处理的最大文本长度从32,768个Token猛增到65,536个Token。 这一改变带来了立竿见影的效果,模型的性能和回答长度都出现了「大幅跃升」。  其他参数设置如下: 学习率:3×10⁻⁶ KL散度系数:0.001 GRPO裁剪比率ϵ:10 推理采样温度:1 每个训练步包含32个独立问题,每步的批大小为512。 每400步,用最新的策略模型替换参考模型。 第一强化学习阶段 在这一阶段,训练数据变得更加多样化。 团队遇到了一个意想不到的挑战:模型的「思维链」(<think>标签内的内容)中频繁出现中英夹杂的「语言混合」现象。虽然这不一定影响最终答案的正确性,但极大地影响了可读性。 为了解决这个问题,他们创造性地引入了一个「语言一致性奖励」:如果模型在处理中文问题时,思维链中中文词汇的比例越高,获得的奖励就越多。 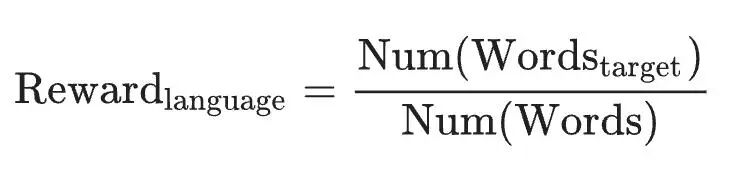 尽管实验表明,强行「矫正」语言会导致模型性能微乎其微的下降,但为了输出结果更符合人类阅读习惯,这个牺牲是值得的。  第二强化学习阶段 在这一阶段,研究人员结合了奖励信号和多样化的提示词分布来训练模型。 推理数据使用基于规则的奖励,通用数据则启用基于模型的奖励。 奖励可以公式化为:  其中  第二阶段保留了第一阶段的大部分参数,但将温度降至0.7,以防因为系数过高造导致生成内容不连贯。 此外,这里还有一个关键操作:基于模型的奖励(有用性和安全性)仅在最后400个训练步中才被引入,从而避免奖励投机的产生。 挑战与未来DeepSeek-R1的诞生,为AI发展带来了深刻的启示,也伴随着新的挑战。 能力局限 在结构化输出和工具使用(如调用计算器、搜索引擎)方面,目前的DeepSeek-R1尚有欠缺。它对提示词非常敏感,不适合复杂的少样本提示,在零样本直接提问时效果最佳。此外,由于强化学习在耗时长的软件工程任务上效率不高,R1在该领域的提升有限。 奖励投机 纯强化学习的成功,完全依赖于可靠的奖励信号。在数学、编程这类有明确对错答案的领域,这很容易实现。但对于像「写一首优美的诗」这样主观的任务,则很难设计完美的奖励模型。如果奖励信号本身有漏洞,策略模型就会像一个聪明的学生钻考试规则的空子一样,「投机取巧」、骗取高分,而不是真正提升能力。 年初,DeepSeek-R1发布后,OpenAI感觉不可思议,指责DeepSeek「可能使用了ChatGPT的输出来训练R1」。  在与审稿人的交流中,DeepSeek表示,R1并非通过复制OpenAI模型生成的推理示例来学习。 不过,与大多数其他大语言模型一样,R1的基础模型是在网络上训练的,因此它会吸收互联网上已有的AI生成的内容。 俄亥俄州立大学AI研究员Huan Sun表示,这一解释「与我们在任何出版物中看到的一样令人信服」。  Nature审稿人、Hugging Face机器学习工程师Lewis Tunstall补充说,其他实验室的复制尝试表明,DeepSeek推理方法已经足够好,不需要这样做。 他说:「我认为现在的证据相当明确,仅使用强化学习就可以获得非常高的性能。」  Lewis Tunstall说,其他研究人员现在正试图应用创建R1的方法来改进现有大语言模型的类似推理能力,并将其扩展到数学和编码以外的领域。他补充说,通过这种方式,R1「开启了一场革命」。  本文内容来源于新智元、小红书,版权归原作者所有,如有侵权请联系删除,谢谢!
|  |Archiver|手机版|小黑屋|Octave中文网学术交流论坛
( 黑ICP备2024030411号-2 )
|Archiver|手机版|小黑屋|Octave中文网学术交流论坛
( 黑ICP备2024030411号-2 )
 发表于 2025-9-20 11:42:08
发表于 2025-9-20 11:42:08